
Être cité, c’est déjà être recommandé.
Cette interview fait partie de notre numéro spécial IA.
Les moteurs de recherche n’en sont plus vraiment. Avec l’essor des modèles de langage génératifs (LLM) comme ChatGPT, Gemini ou LLaMA, les requêtes des internautes ne donnent plus lieu à une liste de liens, mais à des réponses directes, orientées, parfois prescriptives. Pour les marques, ce basculement silencieux transforme radicalement les enjeux de visibilité et d’influence. Il ne suffit plus d’être bien référencé : encore faut-il être cité, compris et bien perçu par les modèles.
C’est dans ce contexte que Jellyfish, agence du groupe The Brandtech, a choisi de se positionner sur le “search LLM” et de développer un nouvel indicateur propriétaire : le “Share of Model”. Un outil qui permet de mesurer la présence et la perception d’une marque dans les réponses générées par les IA. Thomas Skowronski, VP Technology Solutions de Jellyfish, détaille cette approche, les ajustements concrets déjà testés par certaines marques, et les implications profondes de cette mutation pour le marketing, le contenu, le SEO… et le futur du web.
Pourquoi Jellyfish a-t-elle décidé de se positionner sur le search LLM ? Comment définiriez-vous le concept de “Share of Model” en une phrase pour les annonceurs ?
Thomas Skowronski : Jellyfish s’est positionnée sur le search LLM, car on assiste à une évolution structurée du search. Les moteurs de recherche traditionnels sont devenus des modèles de réponse. Aujourd’hui, les utilisateurs ne se contentent plus de rechercher : ils formulent une demande et les LLM leur proposent directement des choix, des produits. Ce n’est plus seulement une question de visibilité sur Google, il s’agit désormais d’être présent dans les réponses générées.
En tant qu’agence, nous accompagnons déjà de nombreux clients sur le search organique et payant, mais ça ne suffit plus. Il faut aller plus loin, se placer en amont pour pouvoir les conseiller. Parce que ce qu’on observe, ce n’est pas juste un changement d’image, c’est un basculement profond dans la manière de consommer l’information. C’est notre rôle de les aider à s’adapter à cette nouvelle réalité.
Quant au “Share of Model”, il mesure la visibilité et la perception d’une marque dans les réponses générées par les modèles d’IA conversationnelle — comme ChatGPT, Gemini ou LLaMA. On analyse non seulement si une marque est mentionnée, mais aussi comment elle est perçue (par exemple : innovante, chère, fiable), et dans quel modèle cette perception varie. L’objectif est de permettre aux marques de se positionner durablement dans ces nouveaux environnements.
Pourquoi est-il devenu stratégique pour une marque d’être “bien perçue” par les modèles d’IA générative ?
T.S. : On n’est plus forcément dans une optique de visibilité, mais dans une optique de mention, dans un premier temps. Et au-delà de ça, en fait, les LLM deviennent des influenceurs à part entière. Ils ne se contentent pas de répondre, ils orientent les utilisateurs dans une direction ou une autre. L’objectif, c’est d’être cité, parce qu’être cité, c’est déjà être recommandé d’une certaine manière.
Si un LLM a une mauvaise perception d’une marque ou d’un produit, ça peut être néfaste, parce qu’il influence directement les utilisateurs. Prenons l’exemple de l’achat d’une voiture électrique : si la marque est perçue comme élitiste, alors qu’elle ne l’est pas, on a un vrai problème. Les LLM ne disent pas forcément la vérité, ils se basent sur les données qu’ils ont intégrées pour construire une perception, mais cette perception peut être fausse.
C’est donc stratégique d’être bien perçu, parce que les LLM deviennent une sorte de monopersona qui va influencer nos futurs consommateurs.

Comment une marque peut-elle agir si elle découvre une réponse erronée ou nuisible ? Avez-vous observé des cas où une marque a vu son image réellement affectée par une réponse générée par IA ?
T.S. : On ne peut pas vraiment pointer une réponse et dire « ça, c’est un problème » pour ensuite le corriger directement. En revanche, on peut renforcer certains signaux pour que les modèles se réentraînent sur ces nouvelles données et modifient leur perception. Ça peut passer par la production d’assets : du contenu texte, des images, de la vidéo, des actions de relations presse aussi. L’idée, c’est d’orienter les modèles avec les bons termes, les bons contenus, pour que leur réponse évolue.
Et oui, des réponses erronées, on en voit à chaque pilote mené avec des marques. Personne ne les avait repérées. Dans l’automobile par exemple, une marque peut être mal perçue sur des sujets comme l’autonomie d’un véhicule électrique, son positionnement prix, ou le caractère innovant de son offre. Le but, c’est d’ajuster ou de créer les bons contenus, les bons termes, pour corriger progressivement la vision que le modèle a d’une marque.
Quelles sont les principales variables que vous analysez pour mesurer cette perception par les LLM ?
T.S. : La première chose qu’on regarde, c’est si la marque est mentionnée dans les réponses. On interroge les modèles sur des milliers de prompts pour voir si elle apparaît. Et si elle apparaît, est-ce qu’elle est citée en haut des réponses ou plutôt en bas. Ensuite, on observe que cette perception est globale, mais qu’elle varie selon les LLM. Ils ne sont pas entraînés sur les mêmes données, donc on peut très bien être bien perçu sur Gemini et mal sur Mistral, par exemple.

C’est pour ça qu’on parle de “share of voice” : il faut savoir où on est bon et où on l’est moins. Et à l’intérieur même de cette perception, on identifie des forces et des faiblesses. Pour une marque, on regarde quels attributs ressortent. Est-ce qu’elle est perçue comme innovante, accessible, bon rapport qualité-prix ? On fonctionne un peu comme avec un entonnoir. À la fin, on obtient un diagnostic qui nous permet de dire : il faut améliorer la perception de tel attribut, sur tel modèle. Et c’est à partir de là qu’on peut adapter la stratégie de communication.
Quels ajustements concrets les marques bêta-testeuses ont-elles pu mettre en place grâce à Share of Model ?
T.S. : Il y a pas mal d’ajustements que les marques bêta-testeuses ont pu tester, même si on ne peut pas forcément tout communiquer. Ce qu’on peut faire, c’est réaligner la sémantique sur certains attributs perçus négativement, par exemple sur l’innovation ou d’autres aspects qu’on aurait identifiés. On peut aussi détecter des biais dans les modèles et essayer d’agir dessus. C’est à dire qu’on ne corrige pas les biais, on modifie les signaux d’entrée pour les atténuer.
Mais il faut garder en tête que les LLM s’entraînent sur des périodes longues, entre six et douze mois. Donc les effets de ces ajustements ne sont pas immédiats. Les modèles vont chercher de nouvelles données, se réentraîner, puis mettre à jour leur perception. C’est un processus progressif qui demande du temps.

Quel rôle jouent les contenus web, les mots-clés ou les visuels dans l’“entraînement” implicite des modèles ?
T.S. : Les LLM apprennent à partir de différentes sources. À la base, ils sont tous partis du web : des sites marchands, de la presse, des forums, des wikis… Donc les contenus qu’on met en ligne jouent un rôle crucial. En ajustant correctement les assets – que ce soit du texte, des visuels ou même la façon dont on structure l’information – on peut influencer la manière dont ces modèles vont percevoir une marque.

Ils repassent sur ces contenus lors de leurs entraînements, et s’ils constatent un changement, ça peut modifier leur vision. Donc oui, les mots-clés, les visuels, tout ce qui est publié en ligne, ça compte énormément dans la construction de leur perception.
Comment Share of Model s’intègre-t-il dans une stratégie marketing plus large, notamment media et SEO ?
T.S. : Share of Model peut s’intégrer dans un pilotage transversal. Au départ, ça sert à comprendre la perception d’un produit ou d’une marque. Mais ensuite, on peut l’articuler avec le SEO, en produisant du contenu optimisé, et mesurer ensuite comment ce contenu est pris en compte par les modèles. À terme, ça peut faire évoluer la perception.
On peut aussi faire le lien avec le paid media, en compensant certaines faiblesses identifiées sur les modèles par des campagnes ciblées. Les assets qu’on produit dans ce cadre-là, que ce soit pour le SEO ou le paid, vont probablement être réutilisés par les GAFAM pour entraîner leurs modèles. Donc c’est positif. On recommande aux clients de produire du contenu dans ce sens-là, en pensant à la fois au référencement, à la communication plus classique, et à l’entraînement futur des modèles.
L’évaluation se fait-elle différemment selon le modèle interrogé (ChatGPT, Gemini, Llama…) ?
T.S. : Oui, forcément, puisque les modèles ne sont pas entraînés sur les mêmes données. On observe des perceptions différentes d’un LLM à l’autre. Par exemple, on peut être très bien perçu sur Gemini et pas du tout sur Llama. C’est normal, parce que chacun a ses propres sources, et certaines sont même propriétaires.
Meta, Google, Amazon… chacun a ses données à lui. Et ça crée des écarts. Les modèles chinois, par exemple, ont des résultats encore différents. Même si tous partent plus ou moins des données publiques du web, les jeux de données utilisés pour l’entraînement varient beaucoup. C’est pour ça qu’on doit adapter l’évaluation à chaque modèle.
Comment anticipez-vous l’évolution de l’influence des LLM dans les décisions d’achat, notamment chez les jeunes générations ? Les LLM deviendront-ils un canal d’influence à part entière dans les stratégies de marque ?
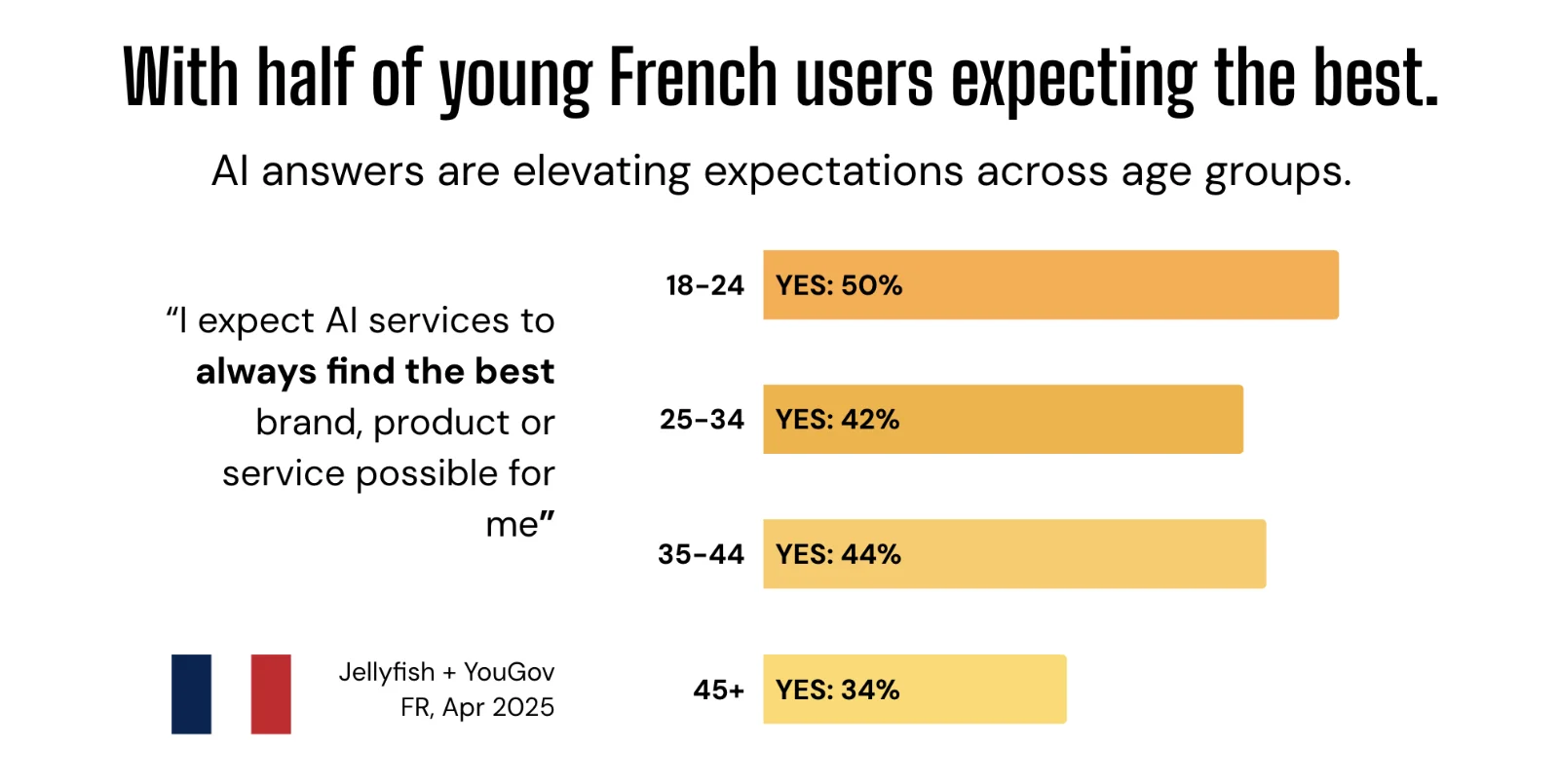
T.S. : Aujourd’hui, 64 % des jeunes utilisent déjà des assistants pour choisir une marque ou un produit. C’est déjà une réalité. J’ai des amis directeurs d’école qui me disent que leurs étudiants trouvent leur établissement via ChatGPT, pas forcément via un salon ou une campagne média. C’est révélateur.
Les jeunes générations sont souvent en avance sur l’adoption des nouveaux outils, mais ça va rapidement s’étendre au-delà. Les LLM sont déjà intégrés à l’écosystème Google, par exemple. Aux États-Unis, ils ont lancé le mode génératif, avec un assistant personnel qui va chercher les infos dans Gmail, Maps, les comparateurs d’hôtels… Il répond à la demande de l’utilisateur sans qu’il ait à quitter l’interface.
Donc oui, ça va devenir un canal d’influence à part entière. Ce n’est même plus un canal en fait : c’est une transformation du web lui-même. On ne va plus naviguer de site en site pour comparer. On va déléguer ce processus au LLM, qui va faire le travail à notre place. Il va nous revenir avec une réponse clé en main. On assiste à un basculement total dans la manière dont l’information est consommée, et ce sont les modèles qui prennent le relais.










