
Les études marketing changent d'échelle.
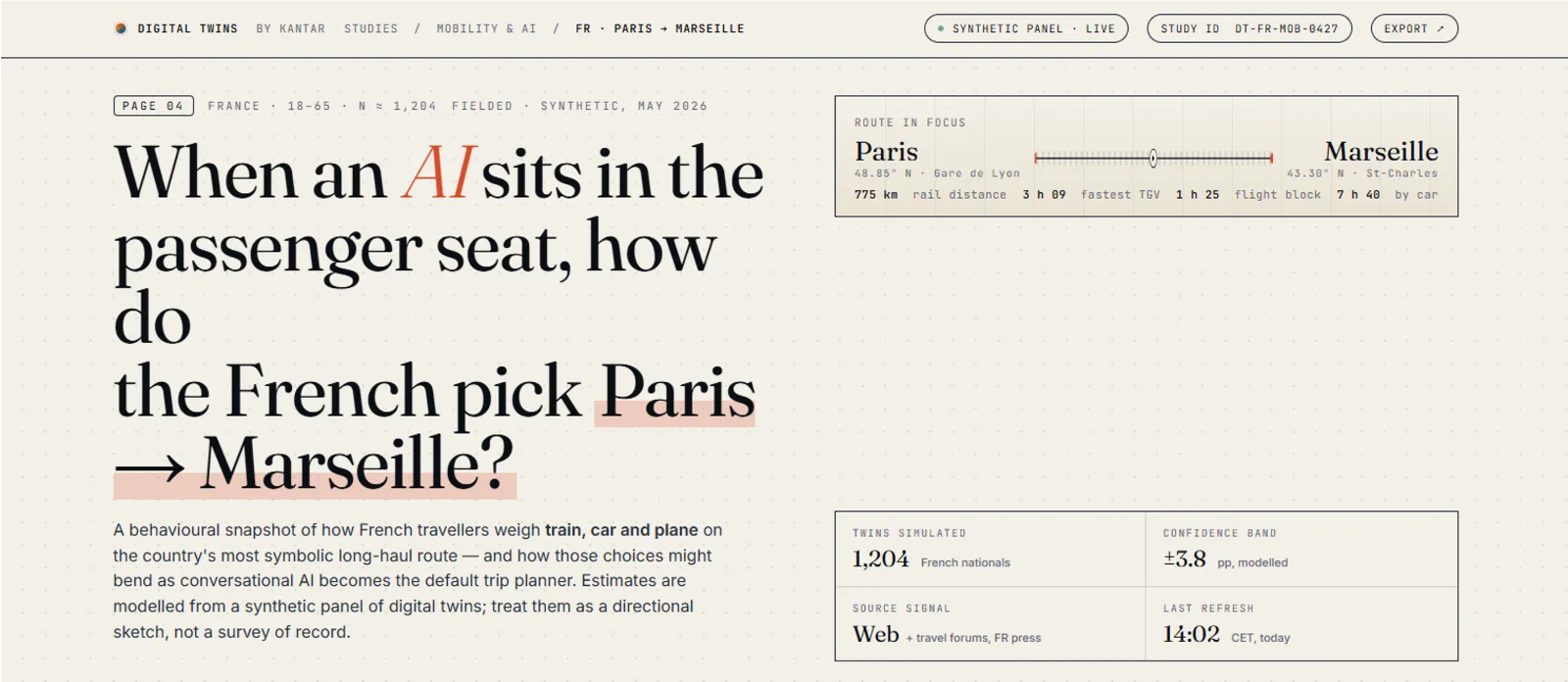
À l’occasion de VivaTech, Kantar a dévoilé Consumer Twins, une nouvelle plateforme qui entend faire évoluer les études marketing à l’ère de l’intelligence artificielle. Son principe : permettre aux marques de dialoguer avec plus de 7,2 millions de jumeaux numériques construits à partir de panélistes réels afin de tester des concepts, des campagnes, des innovations ou des stratégies avant leur déploiement.
À rebours de nombreuses solutions reposant sur des consommateurs synthétiques générés par les LLM, Kantar revendique une approche ancrée dans son panel propriétaire. Pour la Réclame, Cécile Lejeune, présidente de Kantar France, revient sur les choix technologiques qui ont conduit au développement de Consumer Twins, les ambitions de cette nouvelle plateforme, et sa vision d’un marketing où jumeaux numériques, données CRM et IA générative travaillent de concert.
Qu’est-ce qui vous a mené à lancer votre offre de Consumer Twins ? Quelles ont été les étapes qui ont précédé ce lancement ?
C.L. : Nous travaillons sur les jumeaux numériques depuis plus de deux ans grâce à l’IA générative. Plus largement, cela fait déjà de nombreuses années que nous utilisons le machine learning et le deep learning sur nos données, puisque Kantar dispose de plus de cinq milliards de données. L’arrivée de l’IA générative nous a donné l’occasion d’explorer le potentiel des jumeaux numériques, d’abord en interne, sur certaines études.
Au fil de nos expérimentations, nous nous sommes rendu compte que cette technologie pouvait apporter un nouveau service aux marques. Nous avons donc multiplié les phases de test, les POC et les démarches de test and learn pour vérifier que cela fonctionnait réellement.
Au départ, nous avions imaginé créer des jumeaux numériques à partir de profils types ou de personas, comme le font beaucoup d’acteurs. Puis nous avons réalisé que notre véritable force était ailleurs. Nous disposons d’un panel propriétaire extrêmement riche, dans lequel chaque panéliste répond à de nombreux questionnaires, sur des secteurs très différents. Nous avons donc choisi une approche beaucoup plus fine : un panéliste correspond à un jumeau numérique.
Chaque Consumer Twin bénéficie ainsi de toute la connaissance accumulée sur son panéliste. Plus celui-ci participe à des études, plus son jumeau s’enrichit. Aujourd’hui, nous disposons déjà de plus de sept millions de Consumer Twins dans le monde, couvrant tous les profils, tous les secteurs et tous les marchés. C’est ce niveau de couverture qui nous a permis de lancer officiellement l’offre.
Les Consumer Twins intègrent-ils des données synthétiques ou sont-ils uniquement construits à partir de consommateurs réels ?
C.L. : Les Consumer Twins sont bien construits à partir de consommateurs réels issus de notre panel propriétaire. En revanche, la plateforme peut également s’appuyer sur des LLM. Les utilisateurs choisissent d’ailleurs librement de les activer ou non.
L’intérêt des modèles de langage est d’apporter du contexte ou des informations très récentes. Si un sujet d’actualité n’a jamais été abordé dans nos enquêtes, les LLM permettent d’enrichir l’analyse.
Nous pouvons également connecter d’autres données, par exemple les segmentations des clients, leurs Brand Trackers ou d’autres données propriétaires. L’objectif est de réunir plusieurs couches d’information au sein d’une même plateforme afin d’obtenir des analyses marketing plus riches.
Si l’on n’active pas les LLM, un jumeau numérique peut-il répondre à une question à laquelle son panéliste n’a jamais été confronté ?
C.L. : Non. Le jumeau numérique n’invente jamais de réponse. Il ne crée pas de chiffres qui n’existent pas.
S’il existe déjà des données issues d’études réalisées auprès de nos panélistes sur un sujet donné, alors elles pourront être mobilisées. En revanche, si aucune information n’existe, le Consumer Twin ne va pas extrapoler.
Par ailleurs, lorsque des éléments proviennent des LLM, ils sont clairement identifiés dans la plateforme, avec leurs sources. Les données quantitatives ne reposent que sur les réponses issues des Consumer Twins.
Concrètement, comment les clients accèdent-ils à la plateforme ? S’agit-il d’un abonnement ou d’une prestation ?
C.L. : Il s’agit d’un abonnement, auquel s’ajoute un accompagnement de nos équipes. L’accès est organisé par marque et par pays.
Vos clients peuvent-ils importer leurs propres données CRM ?
C.L. : Oui, mais il ne s’agit pas d’importer directement les données brutes du CRM. Ce qui nous intéresse, ce sont surtout les segmentations que les entreprises ont construites à partir de leurs données.
Nous pouvons intégrer ces segmentations dans la plateforme. Les Consumer Twins peuvent ensuite être croisés avec ces segments afin d’analyser les tendances, les attentes ou les réactions propres à chaque population ciblée. C’est cette mise en perspective qui apporte de la valeur.
Comment trouvez-vous le bon équilibre entre les réponses issues des Consumer Twins, celles des LLM et les données des clients ?
C.L. : C’est précisément l’un des enjeux de cette plateforme. Nous devons faire en sorte que les utilisateurs sachent toujours distinguer ce qui provient des Consumer Twins, des LLM ou des données de l’entreprise.
Aujourd’hui, les Consumer Twins restent largement majoritaires dans les analyses produites. Demain, les LLM prendront peut-être davantage de place, au rythme de leur évolution. Nous continuerons également à enrichir notre base de Consumer Twins.
L’équilibre dépendra probablement des secteurs, des marques et des cas d’usage. Notre rôle est justement d’orchestrer intelligemment ces différentes sources de données
Quelle est la prochaine étape dans le développement de Consumer Twins ?
C.L. : Notre priorité est désormais de connecter toujours plus de données clients afin que la plateforme devienne un véritable point d’entrée pour toutes les questions marketing, innovation et relation client.
Aujourd’hui, les premiers clients commencent généralement par un cas d’usage précis, comme l’innovation, l’exploration des tendances ou la marque. L’objectif est ensuite d’élargir progressivement les usages.
À terme, nous voulons réunir au même endroit les données des entreprises, les Consumer Twins et les LLM. Beaucoup de plateformes exploitent déjà les modèles de langage, beaucoup de directions marketing développent également leurs propres hubs de données. Ce qui nous semble vraiment différenciant, c’est de connecter ces données à des consommateurs réels représentés par leurs jumeaux numériques.










